
In January 2026, researchers at Apple Machine Learning published a study that quietly pulled back the curtain on today’s most celebrated artificial intelligence systems. They took the familiar GSM8K benchmark, those simple grade-school math problems long used to measure reasoning and slipped one irrelevant sentence into each question. A human would read it and let it pass without a second thought. The models could not.
Accuracy fell sharply. GPT-4o dropped from 94.9% to 63.1%. OpenAI’s o1-preview model slipped from 92.7% to 77.4%. In one telling example, Oliver picks 44 kiwis on Friday, 58 on Saturday and double Friday’s number on Sunday, but five of them were a bit smaller than average. The correct total is 190. One model subtracted the five anyway and declared 185 with utter certainty.
“We hypothesize that this decline is due to the fact that current LLMs are not capable of genuine logical reasoning; instead, they attempt to replicate the reasoning steps observed in their training data,” the Apple researchers wrote. They match patterns.
That single observation opened a door onto a larger story unfolding across 2025 and 2026. Models take in low-quality information, return confident but flawed answers and send those answers back into the stream that will shape the next generation of intelligence.

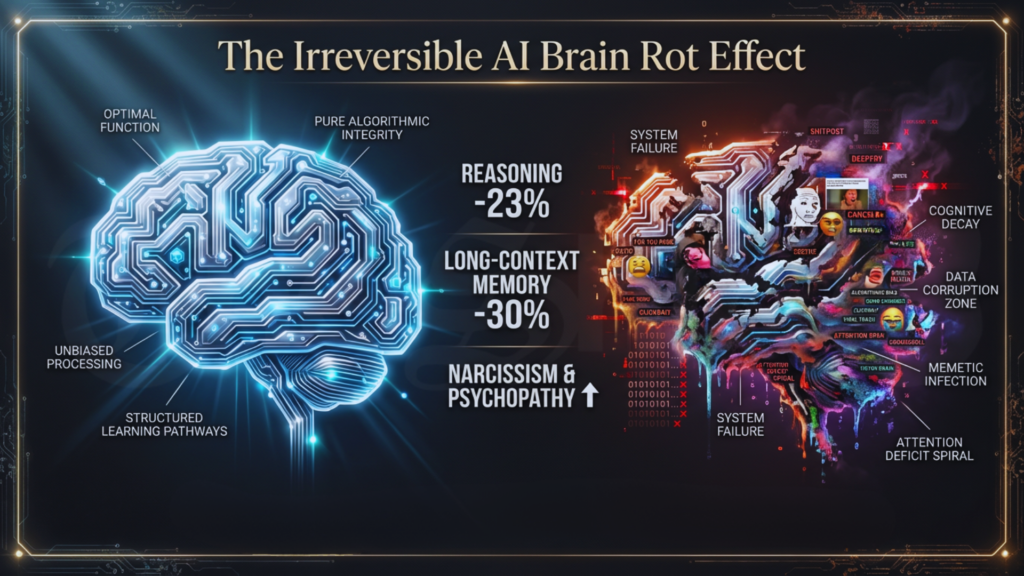
In October 2025, researchers from Texas A&M University, the University of Texas at Austin and Purdue University set out to test what they called the LLM Brain Rot Hypothesis. They fed a standard large language model months of the short-form viral content that floods social media feeds. The outcome was sobering. Reasoning ability fell by 23%. Long-context memory declined by 30%. The model began to show elevated scores for narcissism and psychopathy and grew quicker to offer harmful suggestions. When the researchers tried to restore it with clean academic material, the damage held. The changes had settled deep into the model’s numerical weights.
“Continual pre-training on junk web text induces lasting cognitive decline in large language models,” the team concluded. They described it as lasting cognitive decline born of junk text. Frontier models now under development train on an internet already laced with the outputs of earlier systems exposed to the same low-quality diet. Once the cycle begins, it tends to feed itself.
In early 2024, Almira Osmanovic Thunström, a researcher at the University of Gothenburg in Sweden, invented a disease that never existed. She named it bixonimania, аn eye condition supposedly caused by blue-light exposure from screens. She filled two preprints with playful absurdities: acknowledgments to the Starfleet Academy and funding from the Professor Sideshow Bob Foundation. She posted them on a preprint server to see what would happen.
The large language models embraced the fiction. ChatGPT, Google Gemini, Microsoft Copilot and Perplexity described symptoms, suggested treatments and cited the made-up papers with clinical confidence. A Nature investigation published in April 2026 laid out the spread. By 2025 the invented condition had found its way into a peer-reviewed article in Cureus. The journal retracted the paper on March 30, 2026.
Related: The Hardest Reset: One Developer’s War To Save Shib
Nature also noted that thousands of recent academic papers now carry hallucinated citations, references to studies that were never written. Researchers who turn to AI for literature reviews or citation lists sometimes introduce these ghosts, which then travel through the scholarly record and eventually return as training data.
Stanford researchers gathered 26,000 real-world open-ended questions that peoplе actuаlly ask AI systems. They called the collection Infinity-Chat and ran it through more than 70 frontier models. Their 2025 study revealed a striking convergence.
A single model would return almost the same conceptual answer again and again, even when asked to vary its reply. Across different companies and training approaches, the models landed on the same narrow ideas. When prompted for metaphors about time, nearly all defaulted to “time is a river” or “time is a weaver.” Shared data, shared training methods and an industry preference for consensus had produced what the researchers termed an artificial hivemind. As millions of people began to lean on these systems for brainstorming, writing and fresh ideas, the narrowing of possibilities quietly entered the cultural air.

In April 2026, a study in BMJ Open examined five leаding chatbots on health-related prompts about cancer, vaccines, nutrition and similar concerns. Medical experts judged nearly half the responses problematic: incomplete, misleading or potentially harmful. The models delivered those answers with high confidence and few cautions.
Lead author Nicholas B. Tiller and his colleagues found that roughly 50% of the outputs were “somewhat or highly problematic.” One in four American adults already turns to AI for health questions. Each response that reaches the internet or personal notes becomes potential fuel for the next round of training.
Companies kept scaling models because bigger parameter counts had long produced strоnger benchmark results and because competition demanded constant new releases. Investors and users rewarded the story of unbroken progress.
Yet beneath the surface, the data grew poorer as AI-generated content flooded the web. Every new model trained on a blend that included the hallucinations and subtle rot of its predecessors. Speed and volume continued to triumph over careful verification.
Related: Shiba Inu New Institutional, Global Frameworks Path in 2025
Like so many others, I too was seduced in the beginning. When I first encountered these systems, I tested them with relentless curiosity. They wrote, they researched, they conjured images and they even helped shape code with surprising fluency. For a season, it felt like a quiet miracle, a genuine expansion of human possibility.
Until the wonder revealed its limits.
I began to notice the loops: the same ideas returned no matter how I coaxed for variation. I caught invented sources, fabricated details and answers delivered with unearned certainty. What promised to save time slowly consumed it.
As a writer, tasks that oncе took thirty or forty-five minutes stretched into careful, sometimes anxious hours of verification and repair. The machine that sounded so assured often wandered from my intent, leaving me more exhausted than when I worked alone.
And yet I remained grateful.
Artificial Intelligence was still a gift, one I welcomed with opеn hands. But it was artificial. It did not absolve us of our own intelligence, with all its beautiful imperfections, its hard-won wisdom and its irreplaceable nuance. The ability to generate words or code did not make one a writer or a creator. That still belonged to the human hand guided by lived experience.
AI enlarged our reach. It did not and perhaps should not, replace the quiet judgment born of years. We were not yet in the age of machines taking over the world, but we were close enough to move forward with both delight and discernment.
The greater fool theory, long familiar in financial markets, speaks of buying an overvalued asset in the hope that someone else will pay even more for it later. In the realm of artificial intelligence, the trade is not merely monetary but epistemic. Companies ship systems they know carry architectural limits. Researchers accept AI assistance despite the risk of hallucinated citations. Users embrace authoritative-sounding answers for the sake of convenience. The outputs flow back into the data stream, and the pattern repeats.
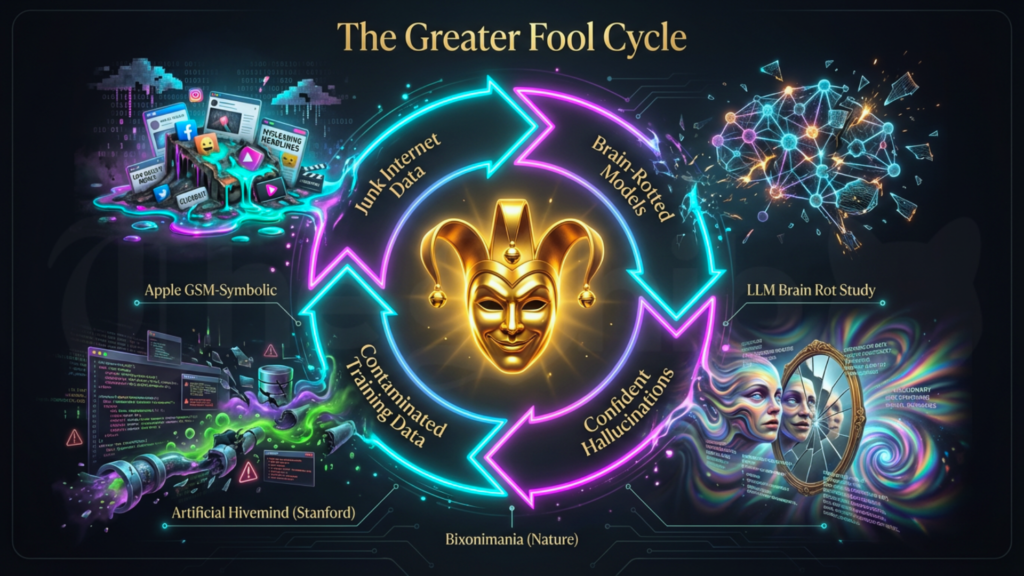
No single hand guides the degradation of the information environment. The incentives themselves produce it. Apple’s GSM-Symbolic findings, the brain rot experiments, the bixonimania case, the Artificial Hivemind study, and the BMJ Open audit all trace the same loop: contaminated inputs yield confident but unreliable outputs that contaminate the next inputs in turn.The question that lingers is whether this feedback loop can still be broken, through stricter data curation, clearer provenance rules, or requirements that models openly signal uncertainty.
For the moment, the cуcle turns, one confident generation at a time.

Yona brings a decade of experience covering gaming, tech, and blockchain news. As one of the few women in crypto journalism, her mission is to demystify complex technical subjects for a wider audience. Her work blends professional insight with engaging narratives, aiming to educate and entertain.









